Without metadata tagged to it, finding a piece of content in an archive is like a giant needle in the haystack exercise.
Metadata serves a number of functions in broadcast workflows, including making video findable and searchable, tracking rights data and automating parts of the workflow. One of the major challenges is that manually entering metadata can result in a hodgepodge of terms or inconsistent results, so automatically tagging content through artificial intelligence (AI) is becoming more common.
Understanding the critical role of metadata in media workflows, vendors offer different ways to add and use metadata and ways to help broadcasters find those valuable clips, or needles in their haystacks of archives.

Tedial’s smartWork NoCode media integration platform
Tedial CEO Julian Fernandez-Campon identifies three categories of metadata. The first is the content metadata, which describes the content itself. The second is the strata, or the timeline and layers in a clip, such as marking a point in a video as a touchdown or violent. And the third is the technical metadata, which relates to the standards and types of video and audio content, such as whether it is UHD.
Tracking Data Through The Supply Chain
That technical piece will likely only become more important as broadcasters focus on combatting deep fakes.
Raoul Cospen, director of business development for EMEA/APAC at Dalet, says the company is working on a feature for Pyramid that will be able to use metadata to track the origin of media to prevent fake news.
Once the capability is available, he says, “news organizations can, through Dalet Pyramid, authenticate their media before it’s getting distributed and the other way around. When we import media, we can see whether the media has been authenticated or not.”
Debra Slater, founder of Three Media, says part of technical data keeps track of the media’s movement through the supply chain. The audit trail is going to become even more important over time as more people collaborate on content, she says.
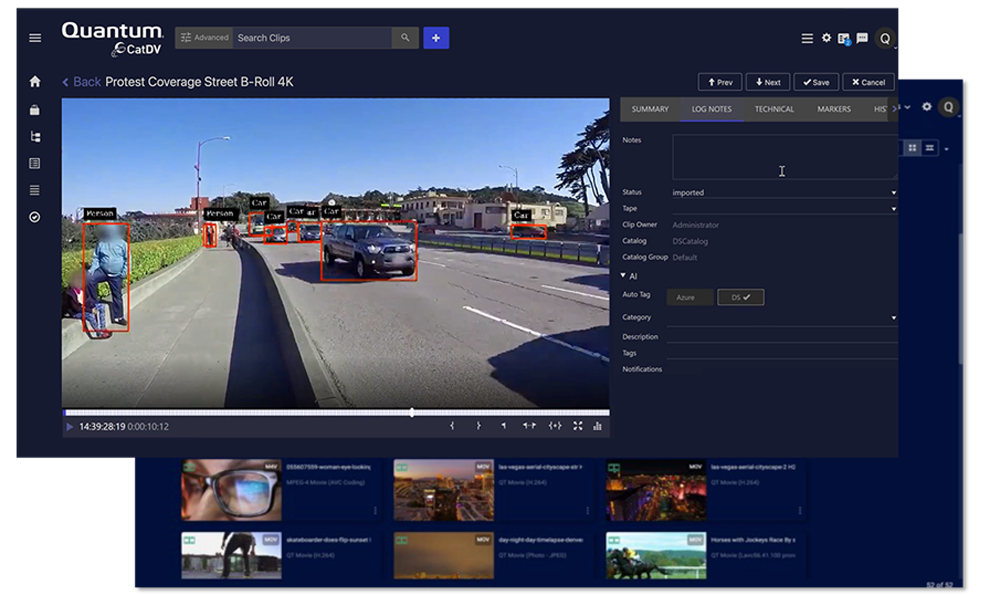
But what’s in the clip is usually what broadcasters are looking for, and artificial intelligence (AI) is helping with recognition of content and turning that information into metadata associated with the media. Such systems can determine faces, places, logos and more.
“All of that information is going to give a wealth of information to content providers,” Slater says.
And that visual data makes it possible for broadcasters to find one clip among thousands of clips in the archives.
Russell Vijayan, director of product at Digital Nirvana, says, “today, archives are unreadable. It’s a pain to get content from archives.”
Unlocking Content’s ‘Massive Value’
Ed Hauber, director of business development at Digital Nirvana, says AI can comb through archival data and generate information about “what year this took place, where it took place, identify faces and names, and other things that technology can extract can then be generated and indexed back to those assets.”

Dalet Pyramid’s planner showcases different story angles and versions for different platforms, a mediabin with the collection of raw material, projects and finished material, work orders and other collaboration objects and their metadata.
But combining transcripts of video with visual intelligence makes content much more easily findable, he says.
Ben Howell, Veritone’s senior director of product management, says applying cognitive data to content “just opens up all these new doors,” making it possible to search for things like faces or happy birthday and receive useful results.
“The AI piece of it is so critical, so important. Not enough people take advantage of the capabilities of it, and when they do, they see so much return on it,” he says.
Steinar Søreide, CTO at Mjoll, Fonn Group, says broadcasters are also relying on metadata to handle licensing and usage rights information for clips.
“They can automate and control where can you publish it,” he says.
Grass Valley Chief Software Architect James Cain says metadata makes content more valuable than un-tagged content. Without it, there’s no provenance for the video so broadcasters don’t know if they can use it, he says.
In short, he says, content has value before metadata is applied, but “massive value” after metadata is applied.
“Metadata is part of a bigger piece. It can make me more efficient, but it makes my whole company more efficient. It is the bedrock on which you can build your workflow,” Cain says.
Metadata’s Challenges
Metadata presents a few challenges, including ensuring the right information is captured, how information is input, the classification system that is used, what happens when pieces of unstandardized metadata live in the same system and how metadata integrates with multiple systems.
Matt Gardner, VIDA’s director of customer success at Visual Data, says “everybody wants metadata, but nobody wants to add metadata.”
Some systems even require metadata to be added before allowing users to proceed to the next step.
“People may start putting in gibberish or some words to be allowed to continue,” Søreide says.
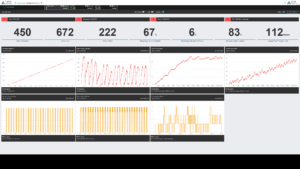
Three Media’s XEN:Pipeline, a cloud based supply-chain workflow management platform, usies customer supplied and workflow and process audit metadata to identify resource bottlenecks.
Because adding metadata to assets manually is laborious and expensive, automatically generated metadata is one sought after solution.
But vendors say planning needs to happen before an entire archive gets tagged to ensure the best metadata results.
“If you don’t have the right metadata to start, it’s going to hurt you throughout the life cycle of your asset,” Gardner says.
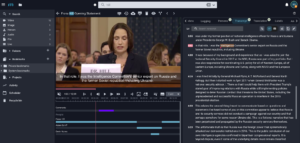
Mjoll’s Mimir shows automated metadata via face detection, with people’s names under the video, as well as via a clickable transcript, making it possible to jump to the position of the clip where that word is spoken.
Metadata generated by different systems may follow different standards or may not be usable on a different platform.
Fernandez-Campon says metadata needs to be merged or normalized so it can be accessed. Tedial’s smartWork platform does that, he says.
Metadata Hygiene
Lacie Romano, Visual Data’s VP of global marketing, says one barrier clients often face in migrating their libraries to the cloud is the hygiene of their metadata, in that there are multiple types of metadata involved with “messy libraries.”
But systems like Visual Data’s VIDA simplifies that migration and cleans up that metadata, she adds.
EditShare CTO Stephen Tallamy says another concern is metadata getting lost as it moves through the workflow. This can be related to how different systems handle metadata and often results in the “lowest common denominator of what” metadata each system can contain, he says.
“It’s the classic cutting floor issue,” he says. “All that metadata was there until it wasn’t.”
In short, broadcasters can be at the “mercy of the lowest common denominator and the vendor’s interpretation of the lowest common denominator” for metadata handling, he says.
Driving The Workflow
The EditShare Flow media asset management system works at a deep integration level with applications like Media Composer and Adobe so there is “more ability for that metadata to power the workflow,” he says. “It’s all very well to have that metadata, but what’s the point of it? To dive the workflow.”
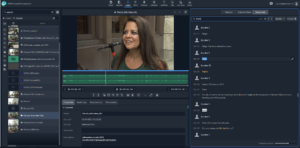
Grass Valley’s AMPP Asset Management uses AI to transcribe audio. Storyboards can then be created quickly by highlighting key parts of the transcript.
Metadata is key for Dalet’s Storytelling 360 workflow, Cospen says. It helps broadcasters manage different versions of stories for different platforms as well as helping track content that is owned and produced out of it. It tracks edited videos and projects and references who is involved with different projects and when content is due, he says.
Archiving On Ingest
Automated workflows can harness AI for metadata at the very earliest stages of the content creation process.
Skip Levans, Quantum’s marketing director of media and entertainment, says sometimes broadcasters find it hard to just keep up with their immediate needs for content, so the notion of archiving content on ingest is gaining traction.
In short, content is tagged on the fly as it enters the asset management system.
“Ingesting with a batch of tags dramatically speeds up production without potentially throwing away something you’ll want later,” Levans says.
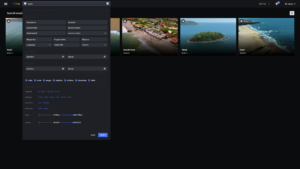
VIDA’s deep metadata search with natural language.
While other metadata can be added later, “passing through the fingertips is the 80% solution,” he adds. After all, “only two minutes of it is going to make it into the package, but the rest of it is only going to make killer B roll. If you can find it.”
Craig Bury, partner and CTO at Three Media, says the costs for using AI are going to decrease, and confidence in accuracy will continue to increase. In the earliest days of using AI for generating metadata, he says, accuracy would “vary wildly” from a small percentage of confidence to 90% and better.
Advances in AI technology translate to much higher quality of metadata, he says.
Garner says it takes time and planning to tag large libraries with metadata, even with AI.
“There’s no magic wand,” he says. “To get it right, you have to spend the time.”
Unlocking Content Value
Levans says it’s worth it.
He says operations without coherent metadata are dogpaddling to keep their heads above water compared to the efficient swimming done by a broadcaster who’s on point with the metadata game.
One of Quantum’s customers “got so good at implementing a metadata plan for all the content they had going back to the 1940s” that adding metadata “became not a chore but a critical way to gain leverage on their content,” he says.
As the racing customer’s library got bigger and better organized, the library became more valuable, Levans says.
“It’s not a linear scale thing. It becomes almost exponentially more valuable,” he says. It unlocks more things you can do, especially when you start to monetize.”















Comments (0)